An N of 1 — subjective feedback
On my run today I was listening to an excellent podcast about Running (very meta I know). This particular episode focused on using…
On my run today I was listening to an excellent podcast about Running (very meta I know). This particular episode focused on using subjective feedback for improving performance rather than only relying on objective feedback in complex adaptive systems (in this case, humans).
We live in a time of wearable technology, with smart watches that can measure all manner of things used by millions of people everyday. And along with the wearable technology are a variety of tools and apps to explore some of the data collected by the technology. I myself have a Garmin watch and have subscriptions to both Strava and TrainingPeaks.
If you explore each of the different tools you will invariably find something which indicates your ‘Fitness’ score. Each has a different algorithm to take data from your wearable and provide you with a fitness score. But is it really indicating my fitness? And does it actually indicate that I am in a better position to perform how I hope to?
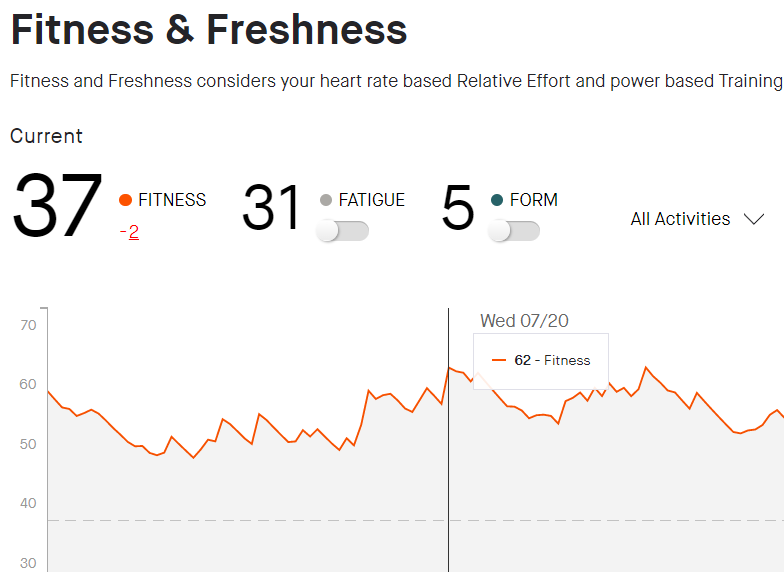
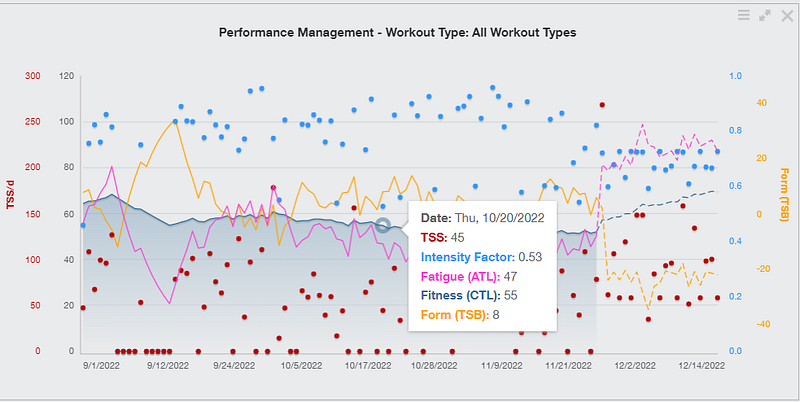
Invariably the fitness score is in fact a score based upon a training load. More training load = a higher fitness score. And yes, in general, training more, will most likely improve fitness. A positive trend on a fitness score will probably indicate that I am getting fitter. But is this the most efficient way of improving my fitness? And most importantly, am I in the best place to perform when I want or need to?
I am an N of 1.
I am an Nof 1. There is only 1 me, there is only 1 you. And yet the ‘fitness score’ is based upon an n of tens, maybe hundreds of thousands. How the average of these tens of thousands respond to specific training loads does not always indicate how I or you will respond or adapt. And this is why subjective feedback is vital.
In the case of running, subjective feedback is often about feel. How do you feel, based upon your training load. And what is the context and conditions of this training? For instance, on today’s run, I undertook a route I know well. It is an 8 mile out and back with lots of elevation. I have ran this route many times, and can look through times and speeds for these runs over the years. But without subjective feedback I am missing a huge part in understanding how my training is going. Today I ran in 30 mph headwinds, visibility was low, it was cold, and I had a bit of a cold myself. All this context is vital in understanding my performance and therefore how my training can be improved and adapted. The most important question to really ask myself is…how did it feel?
Complex adaptive systems
So as much as you are loving reading about my thoughts on running, I’ll get to my actual point. Well the term complex adaptive systems can be used to describe both humans and organisations, and because of this we need to think about both objective and subjective feedback when assessing ourselves and our performance and our actions.
And this can be used both in our data work and also in how we improve our data work. This means we should focus on improving our understanding of the context and environment our data, and the work to improve our data occupies.
Subjective feedback loops in data for action
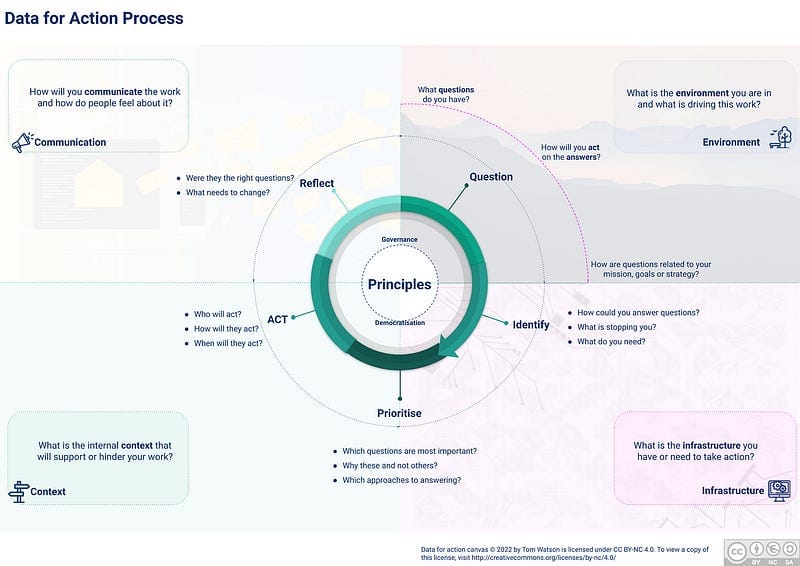
One thing I’m doing a lot of at the moment is supporting organisations to develop their approaches to improving data work within their organisation. Using the Data for Action approach as a starting point this often develops in Data Playbooks and Data Strategies.
One of the areas I think subjective feedback is really important is in understanding how people feel about data and about data work. Data is really only useful if it results in action, and often in organisations data is seen as someone else’s job. I believe democratising data creates better organisations, and to begin this we need to understand, and reflect on how people ‘feel’ about data and data work. This subjective approach to feelings is often overlooked in strategies, in delivery and in building a data culture.
A focus on communication and ‘feelings’ about data are built into my approach to Data for Action and this week I decided to begin working on refining this model and building some resources to support. My starting point for things like this is always to try to get all the key concepts on one page without it being overwhelming. And this is where I got to. I’ve also developed some supporting resources for each of the key concepts, which will follow in the next couple of weeks.
Highlight on a cool new tool
Well, i mean it’s got to be ChatGPT hasn’t it? I could try and talk about something else, but blimey ChatGPT from OpenAI just came and blew many many things out of the water. Ok, so it’s not really a tool, well it is, but it will be some much more. The rise in AI powered tools was already accelerating with GPT3, with AI generated images and tools writing tools like Lex. ChatGPT will take that to a new level. So what is ChatGPT and how could it help you? Good question, and one i asked, umm, it.

Things I’ve found interesting recently
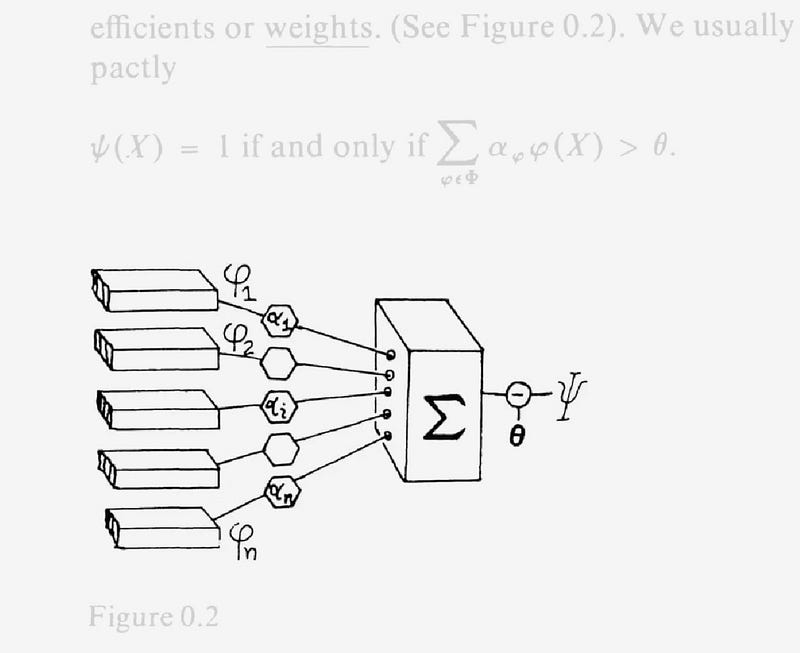
Blueprints for Intelligence: Essays by Philipp Schmitt and Maya Indira Ganesh. I absolutely loved this, both the content and the presentation. ‘Blueprints for Intelligence’ is a visual history of AI told through a collection of diagrams from machine learning research publications published between 1943 and 2020. Looking at the history of AI through its diagrams lets us trace key tendencies in the technology’s evolution.
New Ways of Working Playbook — A notion site with some great resources and studies on New ways of working in progressive organisations.
For some reason, seeing as I do digital work and love principles, I’d not come across Principles for Digital Development before. Reuse and Improve? Yes. Be Data Driven? Yes. Open Standards, Open Data, Open everything? Hell yes.
I thought this blog about decision making, and especially comparing the speed, quality and buy-in of different decision making approaches was a good one.
That’s all folks. Thanks for reading!